
티스토리 뷰
1. VAE(Variational Autoencoder)
VAE는 확률적 생성 모델의 대표 주자이다. 단순한 Autoencoder는 입력을 압축했다가 복원하는 데 집중하지만, VAE는 잠재 공간(latent space)을 확률 분포로 학습한다는 점이 다르다. AutoEncoder는 Image를 Encoding 하여 Embedding Vector 즉 latent vector를 만든 후 이를 Decoder의 input으로 넣어 이미지를 reconstruction 한다. VAE는 이러한 AutoEncoder 방식을 사용하여 input 데이터의 분포 자체를 학습하여 데이터를 생성한다.
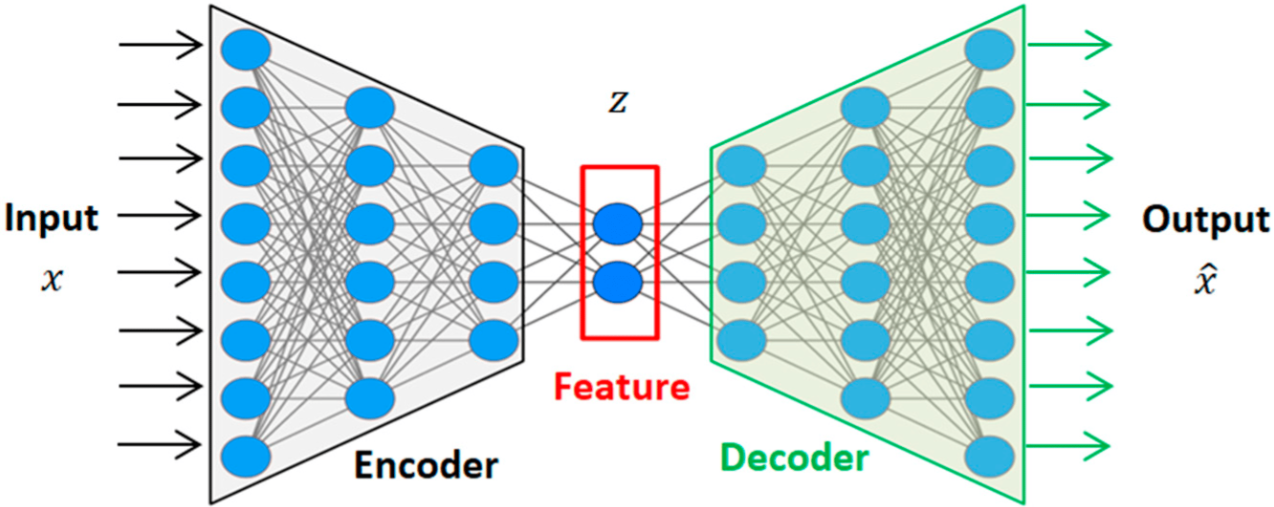
구조
- Encoder: 입력 이미지를 평균과 분산(μ, σ²)으로 표현
- Decoder: 샘플링된 latent vector로부터 이미지를 복원
장점 : 압정적인 학습, 잠재 공간의 해석 가능성
단점 : 생성된 이미지가 상대적으로 블러리하고 디테일 부족
2. VQ-VAE(Vector Quantized VAE)
VAE의 한계를 개선하기 위해 나온 것이 VQ-VAE이다. VQ는 벡터 양자화라는 뜻으로 모델이 강력한 autogressice decoder와 짝을 이룰 때 latent들이 무시되는 'Posterior Collapse' 문제를 피할 수 있다.
VAE에서 내부적으로 취급하는 분포는 대개 Gaussian 분포를 따른다고 가정한다. 확장 버전은 autoregressive prior, posterior model, normalising flow, inverse autoregressive posterior 등을 포함하기도 한다.
VQ-VAE는 여기에 이산 표현을 다루도록 한다. VQ른 사용하면서, posterior과 prior distribution은 categorical하며, 이 분포로부터 생성된 sample은 embedding table을 indexing한다. 이 embeddings는 decoder의 입력으로 들어간다.

VQ-VAE의 구조를 보면, 인코더의 출력을 바로 사용하는 것이 아니라, embedding space(code book)라는 곳에 인코더의 출력 벡터들과 차원이 같은 여러 벡터를 미리 생성해놓고, embedding space에서 인코더의 출력 벡터와 가장 비슷한 벡터를 선택해 교체한다.
위 그림에서 embedding 가 이산표현을 나타낸다. 이를 codebook이라 하며, 는 이산 표현 공간의 크기(-way categorical과 같음), 는 각 embedding vector 의 차원이다.
즉 이며, embedding vector가 개가 있는 것이다.
모델의 encoder는 입력 를 받아 를 출력한다. 이산표현벡터 는 embedding space 에서 가장 가까운 embedding vector를 찾는다(look-up).

그래서 이 모델을 VAE라 할 수 있으며(논문 주장), 를 ELBO로 bound할 수 있다. 제안한 분포 는 deterministic하고 에 대해 단순균등 prior를 정의함으로써 KL divergence를 상수()로 얻을 수 있다.
표현 는 식 1, 2에 주어진 대로 임베딩 중 가장 가까운 원소를 찾고 discretisation bottlenect으로 전달된다.
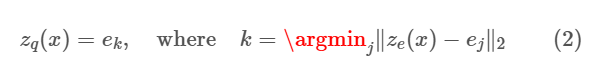
Forward에서는 가 decoder로 전달된다.
Backward에서는 gradient 이 encoder로 그대로 전달된다.
Encoder의 출력과 Decoder의 입력은 차원의 같은 공간에 존재하여, gradient가 어떻게 변화해야 하는지 정보를 줄 수 있다. 전체 objective는 다음 식으로 표현된다.

첫 번째 항은 reconstruction loss으로 위에서 설명한 estimator를 통해 decoder와 encoder를 모두 최적화한다. 실제 이미지와 생성된 이미지 간의 차이를 구하는 loss로 생성된 이미지가 실제 이미지와의 차이가 없도록 만드는 것을 목적으로 한다.
다음으로 VQ loss는 codebook만 update 하는 loss로 codebook vector가 encoder의 출력과 비슷하게 만들도록 하는 목적을 가진다. 여기서 sg는 stop gradient 라는 표기로 encoder ze(x)를 update하지 않는다.
마지막으로 commitment loss이다. commitment loss 는 Encoder만 update 하는 loss로 Encoder의 출력이 codebook vector와 가까운 값을 출력하는 것이 목적인 loss이다.
장점
- latent space 덕분에 보다 선명하고 구조적인 이미지 복원 가능
- 이후 Transformer나 Autoregressive 모델과 결합하기 쉬움
단점
- 여전히 이미지의 fine detail을 복원하는 데 부족
3. VQ-GAN(Vector Quantized GAN)
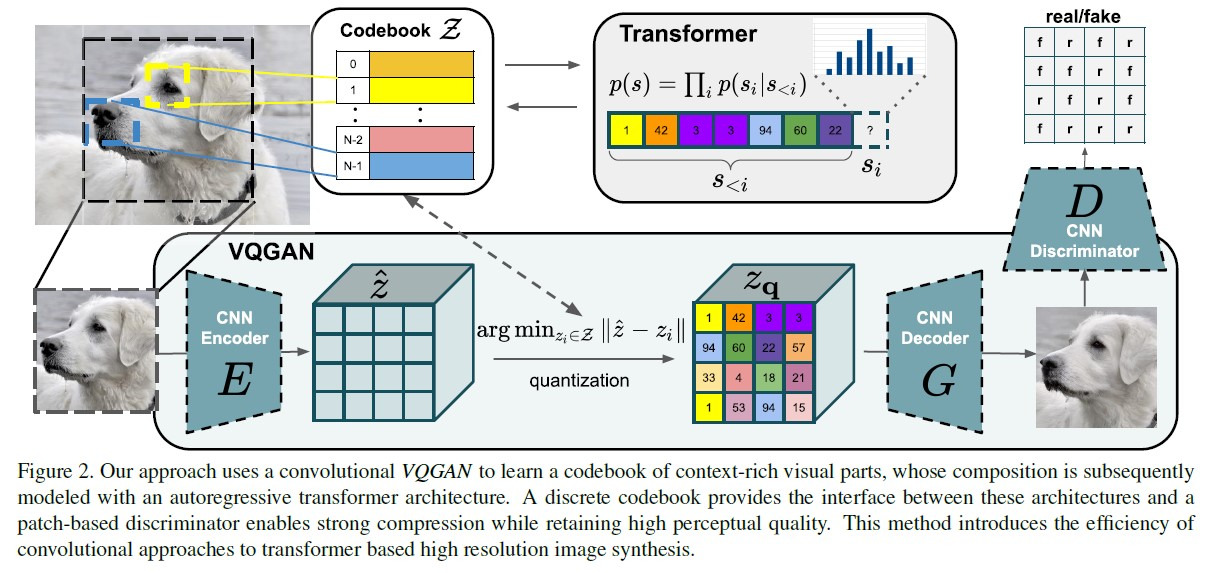
VQGAN은 VQ-VAE의 구조적 장점을 유지하면서, GAN의 Adversarial loss를 도입하여 더 디테일한 이미지를 생성하는데 목적을 두었다. VQGAN은 CNN으로 Locality 를 잘 반영하는 codebook을 학습하고, Transformer의 풍부한 표현력으로 Image Synthesis를 이룬다. VQGAN은 2-stage 모델로 첫번째 stage 에선 codebook을 학습하여 Transformer에 사용하기 위한 이미지의 구성요소를 학습하는 것이고, 2번째 stage에선 이러한 codebook을 바탕으로 구성된 구성요소들로 transformer를 이용하여 이미지를 구성하는 것이다.
3-1 stage 1

첫번째 stage는 codebook 학습하는 단계로 이미지 구성 요소를 학습하는 과정이다. VQGAN의 첫번째 stage는 VQ-VAE와 매우 유사하다. 그러나 VAE와 달리 adversarial learning을 사용하여 학습을 진행한다. VQ-VAE 처럼 Encoder에서 나온 vector 값과 codebook 간의 유클리디안 distance를 비교한 후 distance가 가장 작은 vector zq들의 값으로 quantized vector 를 구성한다. 이렇게 구성한 zq를 decoder에 넣어 reconstruction image를 생성한다. 그리고 이를 discriminator에 넣어 patch 단위로 real 인지 fake 인지 판단한다.
VQ loss


VQ loss에서 달라진 것은 reconstruciont loss이다. 이는 단순 L2 loss 가 아닌 perceptual loss로 VGG 16 기반으로 real image와 fake image를 넣어서 모델 중간중간의 feature map 간의 loss를 구해서 update하는 것이다.
GAN loss
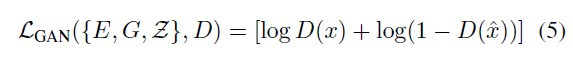
다음으로 Discriminator를 학습하는 loss는 Vanilla GAN loss와 동일하다. 그래서 이 LVQ와 LGAN을 합쳐 최종적인 loss를 설정한다.
Total loss
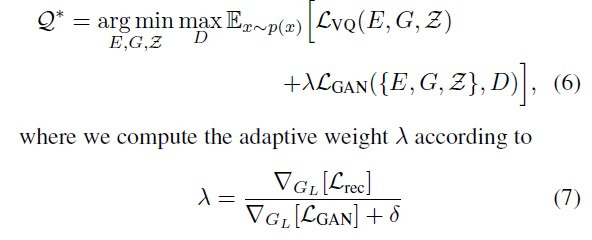
위에서 lambda의 경우, adaptive weight을 의미하며, 이를 바탕으로 VQLoss와 GANLoss 사이에서 어느 하나에 치우치지 않도록 만들어준다. lambda는 Decoder의 마지막 layer에서의 GANLoss, VQLoss의 변화율을 바탕으로 연산된다. 즉, Gan Loss의 변화율이 커질경우 lambda를 작게 유지하여 최종 loss 계산에서 Gan Loss에 패널티를 주는 방식으로 작동한다. 이로서, VQLoss와 GANLoss의 균형을 유지하도록 한다.
3-2 stage 2
Transformer는 앞서 언급했듯이 풍부한 표현력을 갖고 있다. 따라서 본 논문에서는 이러한 특성을 이용하여 Transformer를 Image Synthesis 하는데 사용한다. Transformer는 codebook의 index를 전에 나왔던 값을 기반으로 auto-regressive 하게 예측한다.

위 그림처럼 i 번째 보다 작은 값들을 이용하여 i 번째의 index를 예측하는 것이다. 따라서 이렇게 예측한 i 번째 index 값을 codebook 과 mapping 하여 생성하는 이미지 다음 patch vector를 구성하는 방식이다. 여기서 Transformer는 첫번째 stage 에서 학습한 zq를 label 값으로 삼아 NLL로 학습을 한다.
이러한 Transformer는 unconditional한 상태 뿐만 아니라 conditional한 상태에서도 동일하게 진행이 된다.

여기서 condition은 depth map이나 semantic segmentation map, keypoint , image class 등이 될 수 있다. 이러한 condition은 input 과 마찬가지로 1-stage에서 학습을 하여 각각의 codebook Z와 Zc를 생성한다. 그 후 이를 바탕으로 codebook Zc를 조건으로 주어 다음의 patch 를 예측하게 된다.
3-3 Sliding Attention Window

위 그림처럼 검은색 크기의 임의의 window size를 설정한 후 window size 안에 있는 인접한 patch 들과만 attention을 진행해주는 것이다. 이로 인해 모든 관계를 학습 하는 것이 아닌 주변에 있는 patch 들만을 이용하여 attention을 진행하여 computation을 줄일 수 있다. 하지만 이러한 방법은 landscape 이미지에선 잘 동작이 되지만 공간적인 정보가 많이 변하는 이미지에 대해선 잘 동작이 안되는 한계점이 있다. 이러한 방법을 바탕으로 High-Resolution Image를 잘 만들어 낼 수 있다고 한다.
정리 :
- VAE → 잠재 공간을 확률 분포로 학습 (안정적이지만 블러리)
- VQ-VAE → 잠재 공간을 이산적 코드북으로 변환 (더 선명, 구조적 표현 가능)
- VQGAN → VQ-VAE + GAN (디테일 강화, 텍스트 조건부 확장 가능)
기존의 모델은Transformer의 많은computation으로 인해low-resolution image generation에서만 적용을 하였는데, VQGAN은Transformer를High Resolution생성에 적용할 수 있는 방법론을 제시하였다. 또한 Adversarial learning을 통해서 이미지의 중요한 local structure를 담은 codebook을 생성하는 방식을 제안하였다.
참조
https://blog.naver.com/gypsi12/222977571589
VQ-VAE 간단 정리(+시각화)
목차 1. VAE의 문제점 2. VQ-VAE 아이디어 요약 3. 실제 처리 과정 시각화 4. 학습 방법 5. 이미지...
blog.naver.com
https://greeksharifa.github.io/discrete%20representation/2021/11/07/VQVAE/
Python, Machine & Deep Learning
Python, Machine Learning & Deep Learning
greeksharifa.github.io
https://jjonhwa.github.io/booststudy/2021/12/24/booststudy-paper-VQGAN/
[논문리뷰] VQGAN: Taming Transformers for High-Resolution Image Synthesis
VQGAN: Taming Transformers for High-Resolution Image Synthesis를 읽고 이에 대하여 논의한다.
jjonhwa.github.io
https://bigdata-analyst.tistory.com/349
Taming Transformers for High Resolution Image Synthesis (VQGAN)
https://arxiv.org/abs/2012.09841 Taming Transformers for High-Resolution Image Synthesis Designed to learn long-range interactions on sequential data, transformers continue to show state-of-the-art results on a wide variety of tasks. In contrast to CNNs, t
bigdata-analyst.tistory.com
https://arxiv.org/abs/2012.09841
Taming Transformers for High-Resolution Image Synthesis
Designed to learn long-range interactions on sequential data, transformers continue to show state-of-the-art results on a wide variety of tasks. In contrast to CNNs, they contain no inductive bias that prioritizes local interactions. This makes them expres
arxiv.org
'용어 정리' 카테고리의 다른 글
| GAN 시리즈 - StyleGAN (4) | 2025.08.20 |
|---|---|
| GAN 시리즈 - BigGAN (4) | 2025.08.19 |
| GAN 시리즈 - PGGAN (4) | 2025.08.13 |
| GAN 시리즈 - CycleGAN (4) | 2025.08.13 |
| GAN 시리즈 - WGAN (0) | 2025.08.13 |