
티스토리 뷰
1. WGAN(Wasserstein GAN)
WGAN, 즉 Wasserstein GAN은 전통적인 GAN(Generative Adversarial Network)의 학습 안정성 문제를 해결하기 위해 제안된 모델이다. WGAN의 가장 중요한 특징은 목적 함수와 판별자(discriminator)를 수정하여, 생성자(generator)와 판별자 사이의 경쟁이 더 안정적으로 이루어지도록 한 점에 있다.
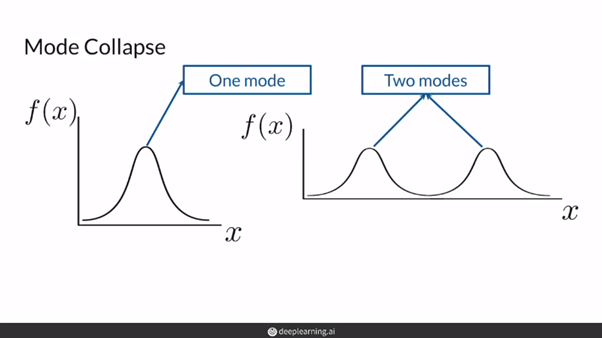
WGAN의 핵심 개념은 세 가지가 있다,
1. Wasserstein 거리 사용
2. Discriminator의 마지막 층에서 시그모이드 활성화 함수 제거, critic으로 기능( 크리틱의 목적은 실제 이미지에 대해서는 높은 값을, 생성된 이미지에 대해서는 낮은 값을 출력한다. 즉, critic은 단순히 '진짜/가짜'를 분류하는 것이 아니라, 데이터의 'realness score'를 출력한다)
3. Weight Clipping
1-1 Wasserstein 거리 (Earth Mover’s 거리)
GAN의 학습 과정에서는 실제 데이터 분포와 generator의 샘플 분포 사이의 거리를 측정해야 한다.
1) Total Variation (TV) distance

- 두 확률 분포 간의 최대 차이를 측정하는 거리이다. 즉, 가능한 측정 값들 중 차이가 가장 큰 값으로 정의된다.
- 두 분포가 완전히 겹치면 0, 겹치지 않으면 1이 된다.
- 불연속적인 변화가 발생하여 gradient descent 기반의 학습이 어렵다.
2) The Kullback-Leibler (KL) divergence

- 두 확률 분포 와 간의 상대 엔트로피를 측정한다.
- 한 분포가 다른 분포를 얼마나 잘 설명하는지를 나타내는 지표이다.
- 분포가 겹치지 않으면 KL divergence는 무한대가 된다.
3) The Jensen-Shannon (JS) divergence

- KL divergence를 대칭적으로 변형한 거리이다.
- 두 분포가 완전히 동일하면 0, 겹치지 않으면 1이 된다.
- 분포가 조금만 차이가 나도 gradient가 거의 0이 되어 학습에 어려움이 있다.
4) The Earth-Mover (EM) distance or Wasserstein-1


- 두 확률 분포 간의 차이를 측정하는 방식으로, 한 확률 분포에서 다른 확률 분포로 이동하는 최소 비용을 의미한다.
- 한 확률 분포를 다른 확률 분포로 변환하는 데 필요한 최소한의 작업량을 기반으로 거리 계산이 이루어진다.
- Gradient가 연속적인 값을 가지므로 gradient descent를 통한 학습이 가능하다.
- 기존 JS/KL divergence보다 더 부드러운 거리를 제공하여 학습 안정성을 향상시켜 분포 간의 차이를 보다 정확하게 반영한다.
Wasserstein GAN은 Wasserstein distance를 최적화하는 것이 목표이며 기존 GAN의 학습 문제를 해결한다.
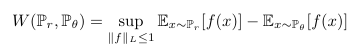
Kantorovich-Rubinstein duality를 이용하여 를 위와 같이 설정한다. 여기서 sup 아래의 의미는 가 1-Lipschitz 함수(두 점 사이의 거리를 일정 비 이상으로 증가시키지 않는 함수)라는 것을 나타낸다. 만약 가 1-Lipschitz가 아니라 어떤 상수 에 대해 K-Lipschitz 조건을 만족하는 경우 아래와 같이 변형된다. 즉, 가 엄격한 1-Lipschitz가 아니더라도, 적절한 K-Lipschitz 조건을 만족하면 Wasserstein distance를 최적화할 수 있다.
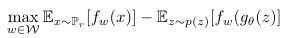
WGAN에서는 최대화 문제를 푸는 함수를 신경망을 이용해 근사하는데 를 학습하는 critic network를 정의하고, 이 critic의 weight 를 최적화하여 Wasserstein distance를 최대화한다.
- 신경망의 가중치 가 compact space 에 놓여 있다고 가정한다.
- 최적화 과정에서 를 이용해 backpropagation을 수행한다.
이 과정에서 기존 GAN의 훈련 과정과 유사하지만 차이점이 있는데, WGAN에서는 critic이 제한 없는 scalar 값을 출력하여 Wasserstein distance를 근사한다. Lipschitz 조건을 만족시키기 위해, weight clipping 또는 gradient penalty를 사용한다.
1-2 WGAN의 학습 과정
1) Critic 학습 단계
- 목표 분포 와 latent 분포 를 각각 미니배치 크기만큼 샘플링.
- Critic의 loss function을 이용하여 weight 를 업데이트.
- Weight clipping 수행: Lipschitz 조건을 강제하기 위해 를 [] 범위로 제한.
2) Generator 학습 단계
- Generator는 critic이 제공하는 Wasserstein distance를 줄이는 방향으로 업데이트
- Critic이 최적화될수록 더 안정적인 gradient 정보를 제공하여 generator 학습을 지원
1-3 Weight Clipping의 한계점 및 문제점
1) 가 너무 큰 경우
- clipping 범위가 넓은 경우
- Lipschitz constraint가 약해지면서 최적의 critic을 찾는 데 오랜 시간이 걸린다.
- 즉, training이 비효율적이 될 수 있다.
2) 가 너무 작은 경우
- clipping 범위가 좁은 경우
- Critic의 weight들이 작은 값에 제한되어 gradient vanishing 현상이 발생.
- 즉, gradient가 너무 작아져 학습이 제대로 진행되지 않는다.

WGAN의 weight clipping은 Lipschitz 조건을 강제하는 방식이지만, 한계가 존재한다. 이 문제를 해결하기 위해 WGAN-GP가 제안되는데 weight clipping 대신 gradient penalty를 추가하여 Lipschitz 조건을 만족하도록 개선한다.
(아직 이해가 안가서 추후 수정 예정)
참조
https://bo-10000.tistory.com/116
[GAN Overview] GAN 주요 모델 정리 (GAN survey 논문 리뷰)
Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy (CSUR 2021) 을 바탕으로, 중요한 GAN 모델들을 정리해 보고자 합니다. 논문에는 더 다양한 모델들이 소개되어 있으나, 그 중 일부만 정리하였
bo-10000.tistory.com
GAN 겉햙기 (GAN 종류)
GAN 은 그 종류가 엄청 많고 또 종류마다 그 쓰임새가 다르다고 말할수 있습니다. 그렇다면 그 GAN 들의 종류는 무엇이며 또 어떤 역할을 하는걸까요? Deep Convolution (DCGAN) 머신러닝과 딥러닝은 생성
baobao.tistory.com
[2025-1] 김유현 - Wasserstein GAN
https://arxiv.org/abs/1701.07875 Wasserstein GANWe introduce a new algorithm named WGAN, an alternative to traditional GAN training. In this new model, we show that we can improve the stability of learning, get rid of problems like mode collapse, and prov
blog.outta.ai
'용어 정리' 카테고리의 다른 글
| GAN 시리즈 - PGGAN (4) | 2025.08.13 |
|---|---|
| GAN 시리즈 - CycleGAN (4) | 2025.08.13 |
| GAN 시리즈 - CGAN (0) | 2025.08.13 |
| GAN 시리즈 - DCGAN (3) | 2025.08.13 |
| GAN 시리즈 - GAN (6) | 2025.08.13 |