
티스토리 뷰
1. GAN(Generative Adversarial Networks)

GAN(생성적 적대 신경망)은 2014년 Ian Goodfellow에 의해 발표된 기술로, 딥러닝 분야에서 매우 중요한 위치를 차지하고 있다. GAN은 구조 자체의 이해가 어렵지 않기 때문에, 다양한 분야에서 많은 연구자들에 의해 연구가 되어왔다. 아래 이미지는 GAN이 제시된 2014년부터 2020년까지 GAN을 주제로 한 논문 수를 나타내는 차트로, 상당히 빠른 속도로 많은 사람들에게 연구가 되어오고 있음을 확인할 수 있다.

1-1 GAN 기본 개념
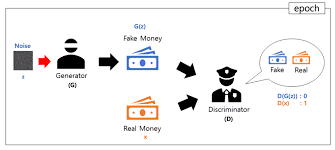
위에 그림은 GAN을 설명할 때 자주 등장하는 그림이다. 지폐 위조범은 최대한 진짜같은 지폐를 만들어 경찰을 속이고, 경찰은 위조지폐범이 만들어낸 지폐와 진짜 지폐를 대조하면서 둘을 구분할 수 있는 차이점을 계속해서 찾아내게 된다. 이 과정에서 위조지폐범은 점점 더 정교한 지폐를 만들어 경찰을 속이기 위해 노력하고 경찰은 완벽히 판별하기 위해 더 노력하게 된다. 서로 경쟁적인 학습이 계속되다보면, 어느순간 경찰이 진짜 지폐와 구분할 수 없을 정도로 비슷한 지폐를 만들 수 있게 될 것이다. 이처럼 GAN에서도 생성모델(generator)은 최대한 진짜 같은 데이터를 만들기 위한 학습을 진행하고, 분류모델(discriminator)은 진짜와 가짜를 판별하기 위한 학습을 진행한다. 이 적대적인 관계는 두 모델이 동시에 발전하도록 자극하며, 결과적으로 더 정교하고 현실적인 데이터를 생성할 수 있게 만든다. 이러한 적대적 학습 방식은 GAN의 독창성과 성능의 핵심이다.
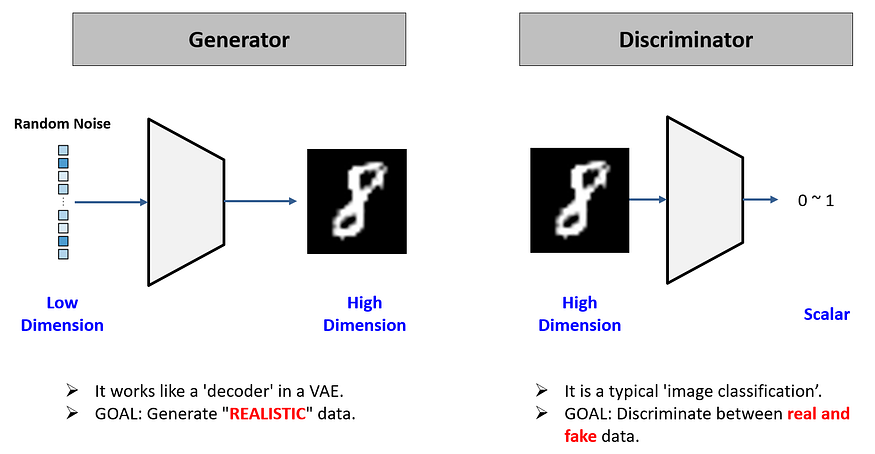
1-2 GAN 원리

먼저 위에 확률밀도함수에 대해 알아보자. 확률밀도함수는 확률변수의 분포를 나타내느 것으로 연속확률변수 x에 대한 f(x)를 의미하는 것이라고 볼 수 있다. 데이터셋들을 학습시킬 때마다 각기 다른 벡터를 가지게 된다.

이렇게 확률밀도함수가 있을 때, GAN 모델이 생성한 이미지가 가지는 확률밀도함수와 둘 사이의 차이가 줄어들면 줄어들 수록 원래의 실제 이미지와 같아지는 원리라고 할 수 있다. 지폐 위조범이 지폐를 만들 때 임의의 종이가 필요한 것처럼, 실제 GAN의 구현에서도 종이의 역할을 하는 noise가 필요하다. 즉 generator가 하는 가짜 데이터를 만드는 일은 noise로부터 진짜 이미지로 맵핑하는 것이라고 볼 수 있다.

- 검은 점선: 원 데이터의 확률분포
- 녹색 점선: 생성자가 만들어 내는 확률분포
- 파란 점선: 판별자의 확률분포
파란 점선인 판별자(Discriminator)는 학습이 진행됨에 따라 GAN이 만들어내는 녹색 점선(Generator)와 분포가 동일해지는 것을 확인할 수 있다. 따라서 (d)의 단계에서는 판별자가 진위를 분류하게 되어도 확률이 같기 때문에 분류를 해도 소용 없게 되며 생성자는 실제 데이터와 매우 흡사하게 이미지를 생성할 수 있게 된다.
1-3 GAN 학습 과정
GAN은 생성자와 판별자의 경쟁구도이며, 경쟁을 통해 균형점(nash equilibrium)을 찾는 것이 목표라 할 수 있다. GAN에서 사용되는 수식은 아래와 같이 간단한 형태이다. G(Generator)를 minimize하고 D(Discriminator)를 maximize한다고 생각하면 된다.

- x : 실제 데이터 포인트
- z : 잠재 공간(latent space)에서 샘플링된 랜덤 노이즈 벡터
- G(z): 생성자 G가 랜덤 노이즈 z를 입력받아 생성한 가짜 데이터(이미지)
- D(x): 판별자 D가 입력 데이터 x에 대해 출력하는 해당 데이터가 진짜일 확률
- 진짜 이미지가 입력인 경우

진짜 이미지를 진짜로 판단한 경우
- D(x) = 0.9 (실제 이미지 x에 대해 판별자가 0.9의 값을 출력)
- 손실 값: -log(0.9)≈ 0.105
진짜 이미지를 가짜로 판단한 경우(높은 Loss이어야 함)
- D(x) = 0.1
- 손실 값: -log(0.1) = 1.0
- 가짜 이미지가 입력인 경우

가짜 이미지를 가짜로 판단한 경우
- D(G(z)) = 0.2
- 손실 값: -log(1–0.2) = -log(0.8) ≈ 0.223
가짜 이미지를 진짜로 판단한 경우(높은 Loss이어야 함)
- D(G(z)) = 0.8
- 손실 값: -log(1–0.8) = -log(0.2) = 1.609
따라서 판별자의 최종 손실은 진짜 이미지와 가까 이미지에 대한 손실 값을 모두 합하여 계산된다.

첫 번째 항은 실제 데이터 x에 대해 판별자가 1에 가까운 값을 출력하도록 한다(최대화)
두 번째 항은 생성된 가짜 데이터 G(z)에 대해 판별자가 0에 가까운 값을 출력하도록 한다(최소화)
Case 1: D(x)를 1로 만드는 경우 (판별자가 모든 것을 분류 가능한 경우)
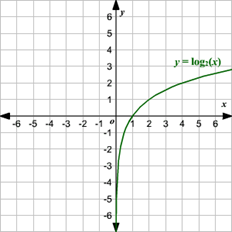
D(x)=1인 상황은 logD(x)를 0으로 만드려는 것과 같다. D(x)=1이라는 의미는 판별자가 모든 것을 다 올바르게 Real/Fake 분류를 할 수 있음을 의미한다. 이렇게 되면 동시에 D(G(z))=1이 된다. 그 이유는 G가 아무리 진짜와 같은 이미지를 생성하더라도 D가 100%의 확률로 전부 잡아낼 수 있기 때문이다. 결과적으로 수식의 앞 부분은 logD(x)는 0이 되어 사라지고, 뒷 부분은 log(1-1)이 되어 무한에 수렴하게 된다. (log 함수 그래프 참조)
Case 2: G(z)를 1로 만드는 경우 (판별자가 모든 것을 분류하지 못하는 경우)
G(z)=1인 상황은 생성자 G가 실제와 구분하지 못할 정도로 흡사하게 만들어 판별자 D가 하나도 구분하지 못하는 상황과 같다. 이렇게 되면 수식의 앞 부분인 logD(x)는 log0이 되어 무한에 수렴하게 되고, 뒷 부분인 log(1-D(G(z))는 0이 되어 사라지게 된다. (이 상황의 경우 minmax요소가 바뀜. min→D, max→G)
1-3 GAN의 장단점
장점
- 고품질의 이미지 생성
GAN은 매우 정교하고 현실적인 이미지를 생성할 수 있다.
- 다양한 응용 가능성
이미지 생성, 데이터 증강, 스타일 변환 등 다양한 분야에 활용할 수 있다.
단점
- 학습 불안정성

GAN은 generator와 discriminator가 서로가 서로를 속이는 과정에서 generator가 data distribution에 근사하는것을 목적으로 한다. 하지만, 번갈아가면서 업데이트를 진행하는 특성상 generator가 좋아지면 discriminator도 좋아지고, discriminator가 좋아지면 generator도 좋아지고, 서로가 서로의 분포에 근사해가면서 끝나지않는 숨바꼭질을 무한히 반복하게 된다. 이로인해 discriminator, generator 모두 서로 자리를 바꾸어가며 쫓아다니게 되고, global optimum에 수렴하지 못하게 된다. 이런 현상을 oscilation이라고 한다.
- 모드 붕괴

GAN을 training 할 때 보여주는 많은 수의 training set 중에서 우연히 딱 하나의 training image 와 비슷한 image 를 generation 했다고 가정해본다. 그렇게되면, 그 이미지와 비슷한 결과물을 냈으니 그 이미지와 최대한 비슷하게 만드는 쪽으로 gradient update가 일어나게 되고 , 상당히 많은 수의 training set을 보여줬음에도 불구하고 몇 가지 이미지에 대해서만 비슷한 결과물을 생성하게 된다.
- 손실값 모니터링의 어려움
GAN의 손실 함수를 모니터링하기 어려워 학습 과정을 추적하는 데 어려움이 있다.
1-4 GAN 실습 코드
[Hands-On] Understanding GAN and Implementation.ipynb
Colab notebook
colab.research.google.com
2. GAN 시리즈

GAN의 종류는 많고 또 그 종류마다 쓰임새 또한 다르다고 말할 수 있다.
참조
https://medium.com/@hugmanskj/gan%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4-a073a5425ef2
GAN에 대한 이해
생성적 적대 신경망(GAN)의 기본 개념, 훈련 방법, 응용 사례를 실용적인 예제와 구현 팁과 함께 살펴보세요.
medium.com
https://roytravel.tistory.com/109
[컴퓨터 비전] All About GAN (Generative Adversarial Nets)
1. GAN 모델 개요 GAN이란 무엇인가? GAN은 Generative Adversarial Nets이라는 논문을 통해 나온 모델로 위와 같이 진짜와 동일해 보이는 이미지를 생성하는 모델이다. 그렇다면 우선 GAN은 언제 만들어졌고
roytravel.tistory.com
https://woochan-autobiography.tistory.com/935
GAN (Generative Adversarial Network)
GAN (Generative Adversarial Network) GAN은 Data를 만들어내는 Generator와 만들어진 Data를 평가하는 Discriminator가 서로 대립(Adversarial)적으로 학습해가며 성능을 점차 개선해 나가자는 개념이다. 여기서 GAN의
woochan-autobiography.tistory.com
https://bo-10000.tistory.com/116
[GAN Overview] GAN 주요 모델 정리 (GAN survey 논문 리뷰)
Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy (CSUR 2021) 을 바탕으로, 중요한 GAN 모델들을 정리해 보고자 합니다. 논문에는 더 다양한 모델들이 소개되어 있으나, 그 중 일부만 정리하였
bo-10000.tistory.com
2) Generative Adversarial Networks (GANs)
## Background GAN은 2014년, Ian Goodfellow의 "Generative Adversarial Network"라는 논문에서 처음 제시되었습니다. CNN의 …
wikidocs.net
GAN 겉햙기 (GAN 종류)
GAN 은 그 종류가 엄청 많고 또 종류마다 그 쓰임새가 다르다고 말할수 있습니다. 그렇다면 그 GAN 들의 종류는 무엇이며 또 어떤 역할을 하는걸까요? Deep Convolution (DCGAN) 머신러닝과 딥러닝은 생성
baobao.tistory.com
'용어 정리' 카테고리의 다른 글
| GAN 시리즈 - CGAN (0) | 2025.08.13 |
|---|---|
| GAN 시리즈 - DCGAN (3) | 2025.08.13 |
| OCR (3) | 2025.07.31 |
| InstructBLIP (3) | 2025.07.30 |
| VQA 시리즈 (3) | 2025.07.30 |