
티스토리 뷰
1. OCR(Optical Character Recognition)
1-1 OCR이란?
OCR(광학 문자 인식)은 자동화된 데이터 추출을 사용하여 텍스트 이미지를 기계가 읽을 수 있는 형식으로 빠르게 변환하는 기술이다. OCR 모델의 구조는 text detection(글자 위치 찾기)와 text recognition(어떤 글자 인지를 인식) 이렇게 두 개로 구성되어있다.

OCR은 스캐너를 사용하여 문서의 물리적 형태를 편집 가능한 디지털 텍스트로 재처리한다. 그 순서는 아래와 같다 :
이미지 획득 : 모든 문서 페이지를 복사한 다음 OCR 엔진이 디지털 문서를 2색 또는 흑백 버전으로 변환 후, 밝은 영역과 어두운 영역 분석한다.
전처리 : 디지털 이미지를 정리하여 외부 픽셀을 제거한다.
텍스트 인식 : 어두운 영역을 기준으로 한 번에 하나의 문자, 단어 또는 텍스트 블록을 대상으로 작업한다. 그 다음 패턴 인식 또는 기능 인식의 두 가지 알고리즘 중 하나를 통해 식별한다.
- 패턴 인식 : OCR 프로그램은 스캔한 문서 또는 이미지 파일의 템플릿과 비교하여 문자를 인식할 수 있도록 다양한 글꼴과 형식의 텍스트 예시에 대해 학습되었다. 이 기능이 작동하기 위해서는 OCR 프로그램에서 이미 학습된 글꼴로 되어 있어야 한다. 다양한 문자를 사용하는 언어를 고려할 때 모든 글꼴과 언어 조합에 대한 학습은 엄청난 시스템 소모가 된다.
- 기능 인식 : OCR 프로그램이 학습되지 않은 글꼴을 분석할 때 사용한다. OCR은 스캔한 문서의 문자를 인식하기 위해 특정 문자 도는 숫자의 기능에 관한 규칙을 적용한다. 기능에는 문자의 사선, 교차선, 루프 도는 곡선의 수가 포함된다. 문자가 식별되면 컴퓨터 시스템에서 추가 조작을 처리하는 데 사용하는 ASCII코드로 변환된다.
레이아웃 인식 : 페이지를 텍스트 블록, 표 또는 이미지와 같은 요소로 나눈다.선은 단어로 구분된 다음 문자로 구분된다. 문자가 선별되면 프로그램은 이를 일련의 패턴 이미지와 비교한다. 일치할 가능성이 있는 모든 항목을 처리한 후 프로그램은 인식된 텍스트를 반환한다.
후처리 : 수집된 정보는 편집 가능한 형식 또는 PDF인 디지털 파일로 저장된다. 일부 시스템은 보다 완벽한 문서 관리를 위해 입력 이미지와 OCR 이후 버전을 모두 유지한다.
1-2 OCR 알고리즘 유형
1) Two stage algorithm : OCR Text Dectetion과 Text Recognition을 분리해서 학습 Pipeline 구성
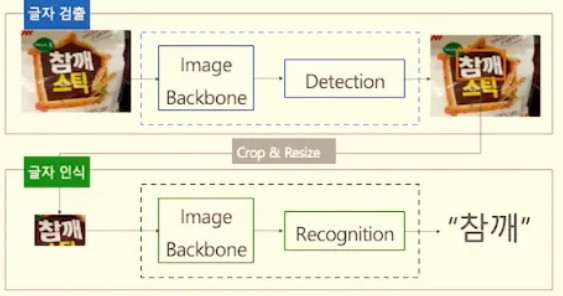
우선 글자를 검출하는 Text Detection은 Object Detection 테스크를 문자 찾기로 확장한 영역이다. Input에는 전체 이미지를 넣고, Output으로는 텍스트가 있는 Bounding Box를 뽑아낸다. 이 때 CNN 기반 모델 알고리즘을 활용한다.
다음 글자를 인식하는 Text Recognition은 검출된 문자가 텍스트로 무엇인지 가려내는 단계이다. Input으로는 텍스트만 있는 이미지가 들어가고, Output으로는 텍스트가 출력된다. 이 때 활용되는 모델로는 attention을 활용한 RNN 계열 모델, Transformer 그리고 CRNN이 있다.
이 알고리즘에서 발생할 수 있는 문제점으로는 글자 검출에서 Bounding Box가 잘못된 경우 글자 인식도 잘못될 경우가 있다. 그 다음은 두 단계가 각자 다른 backbone(특징 추출기)을 쓸 수 있다. 예를 들자면 Detection은 CNN 기반의 ResNet으로 특징을 뽑고, Recognition은 또 다른 CNN+RNN 기반의 구조에서 다시 이미지를 처리한다는 말이다. 이는 즉 같은 이미지를 두 번 다르게 처리하는 구조가 되는 것이다. 이 둘을 하나로 합치는 접근 방식이 E2E OCR 방법론이 된다.
2) End-to-End Scene Text Detection & Recognition : Detection과 Recognition 한번에 E2E OCR 방법론
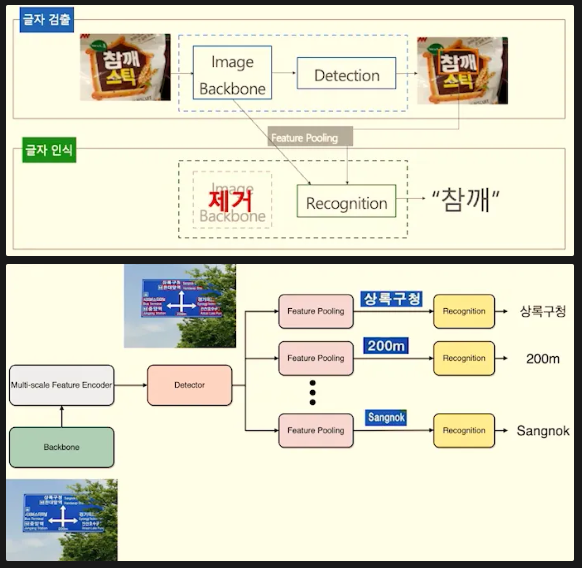
이 방식의 특징으로는 Input으로 전체 이미지를 넣고 Output으로 텍스트가 있는 Bounding Box와 텍스트를 같이 추출한다. 검출과 인식을 한번에 진행함으로서 모델 학습 업데이트 측면에서 편리하게 된다. Image Backbone을 공유함으로서 두 번의 Image Backbone Forward를 거칠 필요가 없어진다. 예시 알고리즘으로는 FOTS(Fast Oriented Text Spotting with a Unified Network) 그리고 DEER (Detection agnostic End to End Recognizer)이 있다.
(FOTS와 DEER 아래 참조)
https://cat-uni.tistory.com/37
FOTS : Fast Oriented Text Spotting with a Unified Network
-개요 / 차별점- 기존에는 Text Detection -> Text Recognition 의 2 stage 모델이 많이 발전했다면, 이 논문에서 말하는 Text Spotting 은 두 stage 를 한번에 하는 것이다. 이렇게 Text Spotting 을 하게 되면, 1. cost 를
cat-uni.tistory.com
https://ainotes.tistory.com/22
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
" data-ke-type="html">HTML 삽입미리보기할 수 없는 소스 이번글에는 NAVER Clova 팀에서 발표한 DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting 라는 모델에 대해 정리해봤습니다.DETR을 기반으로
ainotes.tistory.com
2. OCR-VQA
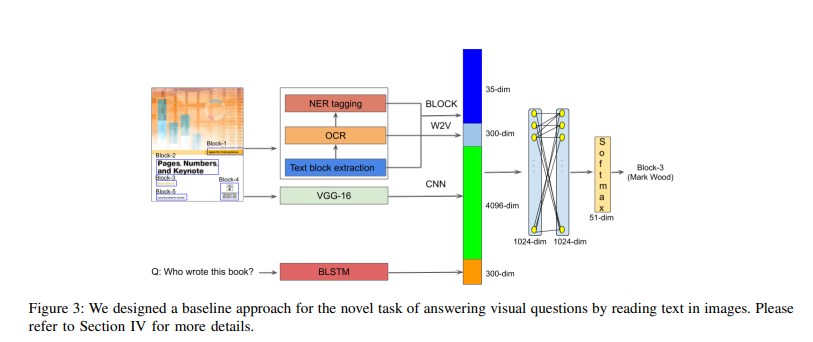
OCR-VQA는 OCR 기술을 기반으로, 이미지 내의 텍스트 정보를 이해하고 해당 정보를 바탕으로 질문에 응답하는 시각 질문응답 과제이다. 이를 위해 OCR-VQA 모델은 이미지 입력을 받아 텍스트 추출 알고리즘을 적용하고, 추출된 텍스트를 자연어 처리 기술을 이용하여 의미 분석을 수행한다. 그리고 질문과 이미지 속 텍스트를 비교하여 정확한 답변을 도출한다.
OCR-VQA 모델은 주로 딥러닝과 자연어 처리 기법을 사용하여 구축되며, 이미지 처리와 텍스트 처리를 결합한 형태다. OCR-VQA 모델은 미리 학습된 신경망을 구성하여 이미지 속 텍스트를 추출하고, 추출된 텍스트와 질문의 의미를 분석하여 답변을 생성한다. OCR-VQA 모델의 훈련 방법은 크게 이미지 속 텍스트 추출 및 분석, 질문과 텍스트의 비교, 답변 생성 과정으로 나뉜다. 훈련 데이터로는 이미지와 그에 대한 질문, 그리고 정답으로 구성된 데이터셋이 사용된다. 이 데이터셋을 이용하여 OCR VQA 모델을 학습시키고, 정확한 답변을 생성할 수 있도록 한다.
3. OCR-VQA와 TextVQA와의 상관관계
| 구분 | 설명 |
| 공통점 | - 둘 다 이미지 내 텍스트 인식(OCR)이 필수다 - 시각 정보와 문자를 결합해 이해하는 능력을 요구된다 - 대부분 scene-text 기반 VQA 모델로 해결된다 |
| 기술 공유 | - OCR 인식기 + VQA 모델이라는 파이프라인을 유사하게 사용된다 - 문자를 추출한 후 텍스트 reasoning 수행하는 구조가 동일하다 - TrOCR, M4C, Donut 같은 모델은 양쪽에 모두 적용 가능하다 |
| 차이점으로 인한 보완성 | - OCR-VQA는 문서에 가까운 이미지이기 때문에, 정형 텍스트 기반 reasoning - TextVQA는 자연 이미지이므로 비정형 텍스트 + 장면 이해가 필요하다. 따라서 하나만으로는 전체 scene-text 이해가 부족하다 |
| 공통 목표 | - "이미지 속 문자와 문맥을 모두 활용한 질문 응답"이라는 목표 공유하고 있다 - 결국 둘 다 텍스트 인식 + 시각적 맥락 reasoning의 문제로 귀결된다 |
예를 들자면 TextVQA의 경우,
[가게 사진]
Q : 이 가게의 이름은 무엇인가요?
= 이미지 속 간판에 있는 글자를 OCR로 읽고, 맥락과 함께 해석이 필요하다
반면에 OCR-VQA의 경우,
[책 표지 이미지]
Q : 이 책의 저저는 누구인가요?
= OCR로 텍스트를 읽은 뒤, 제목/저자/출판사 등을 구분하여 reasoning이 필요하다
결국 둘 다 OCR기반이며 문맥적 reasoning이 필요하지만, 적용 장면과 데이터 도메인이 다르다. 다만 OCR-VQA와 TextVQA는 모두 이미지 내 텍스트를 기반으로 질문에 답하는 테스크이며, 기술적 구조와 목표가 유사하여 서로 높은 상관관계를 가진다.
참조
https://www.ibm.com/kr-ko/think/topics/optical-character-recognition
광학 문자 인식(OCR)이란 무엇인가요? | IBM
광학 문자 인식은 자동화된 데이터 추출과 스토리지 기능을 활용하여 시간, 비용 및 기타 리소스를 절약합니다.
www.ibm.com
https://huidea.tistory.com/312
[1] OCR(Optical Character Recognition) 의 모델 구조, 평가 방법, 사용가능한 API
이번 게시물에서는 OCR(Optical Character Recognition) 의 모델 구조, 평가 방법, 사용가능한 API 종류에 대해 설명하고 다음 게시물에서 각 API 별 장단점과 실제 데이터로 성능을 비교한 결과를 공유하
huidea.tistory.com
[논문 리뷰] ViOCRVQA: Novel Benchmark Dataset and Vision Reader for Visual Question Answering by Understanding Vietnamese
## ViOCRVQA 논문 상세 분석 (한국어) 안녕하세요! ViOCRVQA 논문에 대한 깊이 있는 분석을 요청하셨습니다. 자세한 설명과 함께 핵심 방법론을 기술적인 용어로 풀어 설명드리겠습니다. **1. 논문 개요
www.themoonlight.io
https://www.toolify.ai/ko/ai-news-kr/m3u7ls5gmgcgyqarr7wxczlmgprtdjvg-435241
이미지 내 텍스트 읽기에 의한 시각적 질문 답변 (연구 논문 요약)
이미지 내 텍스트 읽기에 의한 시각적 질문 답변 (연구 논문 요약) var pageOptions = { "pubId": "partner-pub-6153228957310599", "styleId": "1388998650", "relatedSearchTargeting": "content", "resultsPageBaseUrl": "https://www.toolify.ai
www.toolify.ai
OCR-VQA
Bibtex If you use this dataset, please cite: @InProceedings{mishraICDAR19, author = "Anand Mishra and Shashank Shekhar and Ajeet Kumar Singh and Anirban Chakraborty", title = "OCR-VQA: Visual Question Answering by Reading Text in Images", booktitle = "ICDA
ocr-vqa.github.io
'용어 정리' 카테고리의 다른 글
| GAN 시리즈 - DCGAN (3) | 2025.08.13 |
|---|---|
| GAN 시리즈 - GAN (6) | 2025.08.13 |
| InstructBLIP (3) | 2025.07.30 |
| VQA 시리즈 (3) | 2025.07.30 |
| LLM, LMM, LAM (3) | 2025.07.29 |